IEEE MACHINE LEARNING PROJECTS | ARTIFICIAL INTELLIGENCE PROJECTS IN BANGALORE

For Outstation Students, we are having online project classes both technical and coding using net-meeting software
For details, Call: 9886692401/9845166723
DHS Informatics providing latest 2022 – 2023 IEEE projects on IEEE Machine Learning Projects/ Artificial Intelligence projects for the final year engineering students. DHS Informatics trains all students in IEEE Machine Learning Projects/ Artificial Intelligence projects techniques to develop their project with good idea what they need to submit in college to get good marks. DHS Informatics offers placement training in IEEE Machine Learning Projects/ Artificial Intelligence projects at Bangalore and the program name is OJT – On Job Training, job seekers as well as final year college students can join in this placement training program and job opportunities in their dream IT companies. We are providing IEEE Machine Learning Projects/ Artificial Intelligence projects for BE / B TECH, M TECH, MCA, BCA, DIPLOMA students from more than two decades.
Python Final year CSE projects in Bangalore
Machine Learning and Numerical Data
Abstract
In present-day Autism Spectrum Disorder (ASD) is gaining its momentum faster than ever. Detecting autism traits through screening tests is very expensive and time-consuming. With the advancement of artificial intelligence and machine learning (ML), autism can be predicted at a quite early stage. Though a number of studies have been carried out using different techniques, these studies didn’t provide any definitive conclusion about predicting autism traits in terms of different age groups. The proposed model was evaluated with AQ- 10 dataset and 1000 real datasets collected from people with and without autistic traits. The evaluation results showed that the proposed prediction model provides better results in terms of accuracy, specificity, sensitivity, precision, and false-positive rate (FPR) for both kinds of datasets.
Abstract:
Machine Learning algorithms sprawl their application in various fields relentlessly. Software Engineering is not exempted from that. Software bug prediction at the initial stages of software development improves the important aspects such as software quality, reliability, and efficiency and minimizes the development cost. In majority of software projects which are becoming increasingly large and complex programs, bugs are serious challenge for system consistency and efficiency. In our approach, three supervised machine learning algorithms are considered to build the model and predict the occurrence of the software bugs based on historical data by deploying the classifiers Logistic regression, Naïve Bayes, and Decision Tree. Historical data has been used to predict the future software faults by deploying the classifier algorithms and make the models a better choice for predictions using random forest ensemble classifiers and validating the models with K-Fold cross validation technique which results in the model effectively working for all the scenarios.
Abstract:
In this project, two predictive models have been designed namely students’ assessments grades and final students’ performance. The models can be used to detect the factors that influence students’ earning achievement in Universities. With rapid advancements in technology, artificial intelligence has recently become an effective approach in the evaluation and testing of student performance in online courses. Many researchers applied machine learning to predict student performance
Abstract:
Thyroid disease is one of the most common diseases among the female mass in Bangladesh. Hypothyroid is a common variation of thyroid disease. It is clearly visible that hypothyroid disease is mostly seen in female patients. Most people are not aware of that disease as a result of which, it is rapidly turning into a critical disease. It is very much important to detect it in the primary stage so that doctors can provide better medication to keep itself turning into a serious matter. Predicting disease in machine learning is a difficult task. Machine learning plays an important role in predicting diseases. Again distinct feature selection techniques have facilitated this process prediction and assumption of diseases. There are two types of thyroid diseases namely 1. Hyperthyroid and 2.Hypothyroid. Here, in this paper, we have attempted to predict hypothyroid in the primary stage. To do so, we have mainly used three feature selection techniques along with diverse classification techniques. Feature selection techniques used by us are Recursive Feature Selection(RFE), Univariate Feature Selection(UFS) and Principal Component Analysis(PCA) along with classification algorithms named Support Vector Machine(SVM), Decision Tree(DT), Random Forest(RF), Logistic Regression(LR) and Naive Bayes(NB). Thus it’s deduced from our research that RFE helps each classifier to attain better accuracy than all the other feature selection methods used.
Abstract:
Agriculture is an important application in India. Modern technologies can change the situation of farmers and decision-making in the agricultural field in a better way. java is used as a front end for analyzing the agricultural data set. Eclipse IDE is the data mining tool used to predict crop production. The parameter includes in the dataset are precipitation, temperature, reference crop, area, production, and yield for the season from January to December for the years.
Abstract
A non-communicable disease Diabetes is increasing day by day at an alarming rate all over the world and it may cause some long-term issues such as affecting the eyes, heart, kidneys, brain, feet and nerves. It is really important to find an effective way of predicting diabetes before it turns into one of the major problems for the human being. If we take proper precautions on the early stage, it is possible to take control of diabetes disease. In this analysis, 340 instances have been collected with 26 features of patients who have already been affected by diabetes with various symptoms categorized by two types namely Typical symptoms and Non-typical symptoms.
Abstract:
The main objective of this paper is to find the best model to predict the value of the stock market. During the process Of considering various techniques and variables that must be taken into account, we found out that techniques like random forest, support vector machine were not exploited fully. In, this paper we are going to present and review a more feasible method to predict the stock movement with higher accuracy. The first thing we have taken into account is the dataset of the stock market prices from previous year. The dataset was pre-processed and tuned up for real analysis. Hence, our paper will also focus on data preprocessing of the raw dataset. Secondly, after pre-processing the data, we will review the use of random forest, support vector machine on the dataset and the outcomes it generates. In addition, the proposed paper examines the use of the prediction system in real-world settings and issues associated with the accuracy of the overall values given. The paper also presents a machine-learning model to predict the longevity of stock in a competitive market. The successful prediction of the stock will be a great asset for the stock market institutions and will provide real-life solutions to the problems that stock investors face.
Abstract:
Health care field has a vast amount of data, for processing those data certain techniques are used. Data mining is one of the techniques often used. Heart disease is the Leading cause of death worldwide. This System predicts the arising possibilities of Heart Disease. The outcomes of this system provide the chances of occurring heart disease in terms of percentage. The datasets used are classified in terms of medical parameters. This system evaluates those parameters using data mining classification technique. The datasets are processed in python programming using two main Machine Learning Algorithm namely Decision Tree Algorithm and Naive Bayes Algorithm which shows the best algorithm among these two in terms of accuracy level of heart disease.
Deep Learning and Image Processing
Abstract :
Global health has been seriously threatened due to the rapid spread of the Coronavirus disease. In some cases, patients with high risk require early detection. Considering the less RT-PCR sensitivity as a screening tool, medical imaging techniques like computed tomography (CT) provide great advantages when compared. To reduce the fatality CT or X-ray image diagnosis plays an important role. To lessen the burden of radiologists in this global health crisis use of Computer-aided diagnosis is crucial. As a reason, automated image segmentation is also of great benefit for clinical resolution assistance in quantitative research and health monitoring.
Abstract:
Remote sensing image scene classification, which aims at labeling remote sensing images with a set of semantic categories based on their contents, has broad applications in a range of fields. Propelled by the powerful feature learning capabilities of deep neural networks, remote sensing image scene classification driven by deep learning has drawn remarkable attention and achieved significant breakthroughs. However, to the best of our knowledge, a comprehensive review of recent achievements regarding deep learning for scene classification of remote sensing images is still lacking. To be specific, we discuss the main challenges of remote sensing image scene classification using Convolutional Neural Network-based remote sensing image scene classification methods, In addition, we introduce the image preprocessing technique used for remote sensing image scene classification and summarize the performance.
Abstract:
In developing or poor countries, it is not the easy job to discard the Tuberculosis (TB) outbreak by the persistent social inequalities in health. The less number of local health care professionals like doctors and the weak healthcare apparatus found in poor expedients settings.The modern computer enlargement strategies has corrected the recognition of TB testificanduming. In this paper, It offer a paperback plan of action using Convolutional Neural Network (CNN) to handle with um-balanced; less-category X-ray portrayals (data sets), by using CNN plan of action, our plan of action boost the efficiency and correctness for stratifying multiple TB demonstration by a large margin It traverse the effectiveness and efficiency of shamble with cross validation in instructing the network and discover the amazing effect in medical portrayal classification.This plan of actions and conclusions manifest a promising path for more accurate and quicker Tuberculosis healthcare facilities recognition.
Abstract:
Alzheimer disease is the one amongstneurodegenerative disorders. Though the symptoms are benign initially, they become more severe over time. Alzheimer’s disease is a prevalent sort of dementia. This disease is challenging one because there is no treatment for the disease. Diagnosis of the disease is done but that too at the later stage only.if the diseases predicted earlier, the progression or the symptoms of the disease can be slow down. This paper uses Deep learning algorithms to predict the Alzheimer disease using MRI images. This paper we proposed deep learning algorithm CNN along with that we used Gabor filter for extract the feature from MRI images and make use of all this we are able to achieve high accuracy
Abstract:
This paper dealt with the breed classification of dogs. To classify dog breed is a challenging part under a deep convolutional neural network. A set of sample images of a breed of dogs and humans are used to classify and learn the features of the breed. The images are converted to a single label of dimension with image processing. The to find the existing percentage of features in humans of dogs and dogs of human. This research work has used principal component analysis to shorten the most similar features into one group to make an easy study of the features into the deep neural networks. And, the facial features are stored in a vector form. This prepared vector will be compared with each feature of the dog into the database and will give the most efficient result. In the proposed experiment, 13233 human images and 8351 dog images are taken into consideration. The images under test are classified as a breed with the minimum weight between test and train images. This paper is based on research work that classifies different dogs breed using CNN. If the image of a dog is supplied then the algorithm will work for finding the breed of dog and features similarity in the breed and if the human image is supplied it determines the facial features existing in a dog of human and vice-versa.
ABSTRACT:
At present, the existing abnormal event detection models based on deep learning mainly focus on data represented by a vectorial form, which pay little attention to the impact of the internal structure characteristics of feature vector. In addition, a single classi er is dif cult to ensure the accuracy of classi cation. In order to address the above issues, we propose an abnormal event detection hybrid modulation method via feature expectation subgraph calibrating classi cation in video surveillance scenes in this paper. Our main contribution is to calibrate the classi cation of a single classi er by constructing feature expectation subgraphs. First, we employ convolutional neural network and long short-term memory models to extract the spatiotemporal features of video frame, and then construct the feature expectation subgraph for each key frame of every video, which could be used to capture the internal sequential and topological relational characteristics of structured feature vector. Second, we project expectation subgraphs on the sparse vector to combine with a support vector classi er to calibrate the results of a linear support vector classi er. Finally, the experiments on a common dataset named UCSDped1 and a coal mining video dataset in comparison with some existing works demonstrate that the performance of the proposed method is better than several the state-of-the-art approaches.
Abstract:
Among the many types of cancers, bone cancer is one with which most of the deaths occur in the world. Around 10000 deaths are occurring in a year in India due to bone cancer. Bone cancer is the most dangerous and deaths can be avoided if it is detected in the early stage. Here, an automatic bone cancer detection system is proposed to aid oncologists in the early detection of bone cancers and helps them to undergo a timely treatment. Support Vector Machine (SVM) based M3 filtered and Fuzzy C-Means (FCM) segmentation method is proposed to detect bone cancers.
Abstract:
Agriculture plays an important role in the economy of any country and there are a lot of varieties of crops for farmers. The problem or issues occurs when the crops are infected by some disease and the farmers do not know about that disease of plants at the right time. And when the disease is detected, the farmers do not know which disease it is. Therefore, the examination of automatic leaf disease detection in agriculture is a fundamental subject of research as it could display advantages in the observation of vast fields of yields and thus identify manifestations of disease as they occur on plant leaves. The study of plant disease means the study of different patterns visible with the eyes above the plants’ leaves. By looking at the different color and texture features of the same plant, now it can be analyzed that which portion of the plant is healthy and which part of the plant has a disease. The process of knowing the disease of the plant occurs in the laboratory. This process takes a lot of time and it is very expensive. For that, the researcher used different types of techniques so that disease will be detected on time and expenses should be reduced. So, this research work attempts to describe the approach suggested by the study articles. Different scholars view the images in terms of Artificial Intelligence, Machine learning and demonstrate their achievements and problems that still exist. To draw some assumptions, our study of the various approaches suggested is also given. Image Acquisition, Image Preprocessing, Image segmentation, Feature Extraction and Statistical Analysis, Classification based on classifier are the key steps for the identification of diseases. This paper provides, along with the available datasets, a survey of the available approaches to solving the problem discussed.
Abstract:
Abstract:
Machine Learning and Natural Language Processing
Abstract:
Since corona virus has shown up, inaccessibility of legitimate clinical resources is at its peak, like the shortage of specialists and healthcare workers, lack of proper equipment and medicines, etc. The entire medical fraternity is in distress, which results in numerous individual’s demise. Due to unavailability, individuals started taking medication independently without appropriate consultation, making the health condition worse than usual. As of late, machine learning has been valuable in numerous applications, and there is an increase in innovative work for automation. This paper intends to present a drug recommender system that can drastically reduce specialist’s heap. In this research, we build a medicine recommendation system that uses patient reviews to predict the sentiment using various vectorization processes like Bow, TF-IDF,Word2Vec, and Manual Feature Analysis, which can help recommend the top drug for a given disease by different classification algorithms. The predicted sentiments were evaluated by precision, recall, f1score, accuracy, and AUC score.
Abstract:
Stress disorders are a common issue among working IT professionals in the industry today. With changing lifestyle and work cultures, there is an increase in the risk of stress among the employees. Though many industries and corporates provide mental health related schemes and try to ease the workplace atmosphere, the issue is far from control. In this paper, we would like to apply machine learning techniques to analyze stress patterns in working adults and to narrow down the factors that strongly determine the stress levels. Towards this, data from the OSMI mental health survey 2017 responses of working professionals within the tech-industry was considered. Various Machine Learning techniques were applied to train our model after due data cleaning and preprocessing. The accuracy of the above models was obtained and studied comparatively. Boosting had the highest accuracy among the models implemented. By using Decision Trees, prominent features that influence stress were identified as gender, family history and availability of health benefits in the workplace. With these results, industries can now narrow down their approach to reduce stress and create a much comfortable workplace for their employees.
Abstract:
Nowadays, a massive amount of reviews is available online. Besides offering a valuable source of information, these informational contents generated by users, also called User Generated Contents (UGC) strongly impact the purchase decision of customers. As a matter of fact, a recent survey revealed that 67.7% of consumers are effectively influenced by online reviews when making their purchase decisions. The consumers want to find useful information as quickly as possible. However, searching and comparing text reviews can be frustrating for users as they feel submerged with information. Indeed, the massive amount of text reviews as well as its unstructured text format prevent the user from choosing a product with ease. The star-rating, i.e. stars from 1 to 5 on Amazon, rather than its text content gives a quick overview of the product quality. This numerical information is the number one factor used in an early phase by consumers to compare products before making their purchase decision. However, many product reviews are not accompanied by a correct scale rating system, some of reviewers given good review but the rating is low and bad review but high ratings so we might get some wrong product to overcome this problem we proposed model using Natural language processing (NLP), and Deep Learning Algorithm. Natural language processing (NLP) is a subfield of linguistics, computer science, and artificial intelligence concerned with the interactions between computers and human language, in particular how to program computers to process and analyze large amounts of natural language data. NLP is used for Text processing here, then we used Recurrent Neural Network (RNN) based Long short-term memory (LSTM) for classify the Ratings based on Reviews. Long short-term memory (LSTM) is an artificial recurrent neural network (RNN) architecture used in the field of deep learning. LSTM networks are well-suited to classifying, processing and making predictions based on text data.
Abstract:
With the increasing demand of social life in today’s world one famous platform known to be as Twitter plays important role for every citizen to connect socially, whether in the form of tweeting a tweet for other person or exploring various fields in the running world. But this platform, now a days gets infected by some spammers, with the intention of increasing traffic in their spam web sites they connect their URL with the informative tweet where there is no relation between the content present in URL and the tweet message, these are called spammed tweets. This paper provides a unique approach to detect whether the tweet mentioned by the user is spam or not spam using the encoder decoder technique used with vectorizer converter on the mentioned tweets and on its linked URL, which leads to the prediction of similarity score between them.
Abstract:
Today’s world is solely dependent on social media. A number of mental disorders caused by social network are seen such as cyber Addiction, net Compulsion etc. this becomes more problematic when there is delayed clinical intervention. We are preparing project where it can detected in early stages. We take face images of a particular user where each image depicts an expression and is categorized as positive or negative. We have 6 expressions. They are: sad, normal, happy, angry, surprise, disgust. Where expressions such as sad, anrgry and disgust are concluded as negative and normal, happy and surprise is concluded as positive. For certain person if we are having more negative depiction then it is concluded to be a mental disorder. We use image processing with Convolution Neural Networks for the detection and prediction.
Abstract:
Women and girls have been experiencing a lot of violence and harassment in public places in various cities starting from stalking and leading to sexual harassment or sexual assault. This research paper basically focuses on the role of social media in promoting the safety of women in Indian cities with special reference to the role of social media websites and applications including Twitter platform Facebook and Instagram. This paper also focuses on how a sense of responsibility on part of Indian society can be developed the common Indian people so that we should focus on the safety of women surrounding them. Tweets on Twitter which usually contains images and text and also written messages and quotes which focus on the safety of women in Indian cities can be used to read a message amongst the Indian Youth Culture and educate people to take strict action and punish those who harass the women. Twitter and other Twitter handles which include hash tag messages that are widely spread across the whole globe sir as a platform for women to express their views about how they feel while we go out for work or travel in a public transport and what is the state of their mind when they are surrounded by unknown men and whether these women feel safe or not?
Abstract:
With the rapid development of Internet technology and social networks, a large number of comment texts are generated on the Web. In the era of big data, mining the emotional tendency of comments through artificial intelligence technology is helpful for the timely understanding of network public opinion. The technology of sentiment analysis is a part of artificial intelligence, and its research is very meaningful for obtaining the sentiment trend of the comments. The essence of sentiment analysis is the text classification task, and different words have different contributions to classification. In the current sentiment analysis studies, distributed word representation is mostly used. However, distributed word representation only considers the semantic information of word, but ignore the sentiment information of the word. In this paper, an improved word representation method is proposed, which integrates the contribution of sentiment information into the traditional TF-IDF algorithm and generates weighted word vectors. The weighted word vectors are input into bidirectional long short term memory (BiLSTM) to capture the context information effectively, and the comment vectors are better represented. The sentiment tendency of the comment is obtained by feed forward neural network classifier. Under the same conditions, the proposed sentiment analysis method is compared with the sentiment analysis methods of RNN, CNN, LSTM, and NB. The experimental results show that the proposed sentiment analysis method has higher precision, recall, and F1 score. The method is proved to be effective with high accuracy on comments.
Abstract:
we are living in a post modern era and there are tremendous changes happening to our daily routines which make an impact on our health positively and negatively. As a result of these changes various kind of diseases are enormously increased. Especially, heart disease has become more common these days. The life of people is at a risk. Variation in Blood pressure, sugar, pulse rate etc. can lead to cardiovascular diseases that include narrowed or blocked blood vessels. It may causes Heart failure, Aneurysm, Peripheral artery disease, Heart attack, Stroke and even sudden cardiac arrest. Many forms of heart disease can be detected or diagnosed with different medical tests by considering family medical history and other factors. But, the prediction of heart diseases without doing any medical tests is quite difficult. The aim of this project is to diagnose different heart diseases and to make all possible precautions to prevent at early stage itself with affordable rate. We follow ‘Data mining’ technique in which attributes are fed in to SVM, Random forest, KNN, and ANN classification Algorithms for the prediction of heart diseases. The preliminary readings and studies obtained from this technique is used to know the possibility of detecting heart diseases at early stage and can be completely cured by proper diagnosis.
Abstract :
Human Activity Recognition (HAR) based on sensor networks is an important research direction in the fields of pervasive computing and body area network. Existing researches often use statistical machine learning methods to manually extract and construct features of different motions. However, in the face of extremely fast-growing waveform data with no obvious laws, the traditional feature engineering methods are becoming more and more incapable. With the development of Deep Learning technology, we do not need to manually extract features and can improve the performance in complex human activity recognition problems. By migrating deep neural network experience in image recognition, we propose a deep learning model (InnoHAR) based on the combination of Inception Neural Network and recurrent neural network. The model inputs the waveform data of multi-channel sensors end-to-end. Multi-dimensional features are extracted by Inception-like modules with using of various kernel-based convolution layers. Combined with GRU, modeling for time series features is realized, making full use of data characteristics to complete classification tasks. Through experimental verification on three most widely used public HAR datasets, our proposed method shows consistent superior performance and has good generalization performance, when compared with state-of-the-arts.
IEEE MACHINE LEARNING PROJECTS / ARTIFICIAL INTELLIGENCE PROJECTS IN BANGALORE
Project CODE |
TITLES |
BASEPAPER |
SYNOPSIS |
LINKS |
|---|---|---|---|---|
| 1. | IEEE :Application of machine learning in recommendation systems |  |
||
| 2. | IEEE :Breast Cancer Diagnosis Using Adaptive Voting Ensemble Machine Learning Algorithm | |
||
| 3. | IEEE :Classifying Depressed Users With Multiple Instance Learning from Social Network Data | |
||
| 4. | IEEE :Research on Personalized Referral Service and Big Data Mining for E-commerce with Machine Learning | |
||
| 5. | IEEE: Zaman Serisi Verilerini Kullanarak Makine Öğrenmesi Yöntemleri ile Bitcoin Fiyat Tahmini Prediction of Bitcoin Prices with Machine Learning Methods using Time Series Data | |
||
| 6. | IEEE :Supervised Machine Learning Algorithms for Credit Card Fraudulent Transaction Detection: A Comparative Study | |
||
| 7. | IEEE :Machine Learning Approach for Brain Tumor Detection | |
||
| 8. | IEEE :Leveraging Deep Preference Learning for Indexing and Retrieval of Biomedical Images | |
||
| 9. | IEEE :Animal classification using facial images with score-level fusion | |
||
| 10. | IEEE :Credit card fraud detection using Machine Learning Techniques | |
||
| 11. | IEEE :Phishing Web Sites Features Classification Based on Extreme Learning Machine | |
||
| 12. | IEEE :Predictive Analysis of Sports Data using Google Prediction API | |
||
| 13. | IEEE :Point-of-interest Recommendation for Location Promotion in Location-based Social Networks |  |
|
|
| 14. | IEEE :NetSpam: a Network-based Spam Detection Framework for Reviews in Online Social Media | |
|
|
| 15. | IEEE :SocialQ&A: An Online Social Network Based Question and Answer System | |
|
|
| 16. | IEEE :Modeling Urban Behavior by Mining Geotagged Social Data | |
|
|
| 17. | IEEE :SPORE: A Sequential Personalized Spatial Item Recommender System | |
|
|
| 18. | IEEE : Truth Discovery in Crowd sourced Detection of Spatial Events | |
|
|
| 19. | IEEE : Sentiment Analysis of Top Colleges in India Using Twitter Data | |
|
DHS Informatics believes in students’ stratification, we first brief the students about the technologies and type of IEEE Machine Learning Projects/ Artificial Intelligence projects and other domain projects. After complete concept explanation of the IEEE Machine Learning/Artificial Intelligence projects, students are allowed to choose more than one IEEE Machine Learning projects for functionality details. Even students can pick one project topic from IEEE Machine Learning Projects/ Artificial Intelligence projects and another two from other domains like Machine Learning /AI, Data Science, image process, information forensic, big data,block chain etc. DHS Informatics is a pioneer institute in Bangalore / Bengaluru; we are supporting project works for other institute all over India. We are the leading final year project center in Bangalore / Bengaluru and having office in five different main locations Jayanagar, Yelahanka, Vijayanagar, RT Nagar & Indiranagar.
We allow the ECE, CSE, ISE final year students to use the lab and assist them in project development work; even we encourage students to get their own idea to develop their final year projects for their college submission.
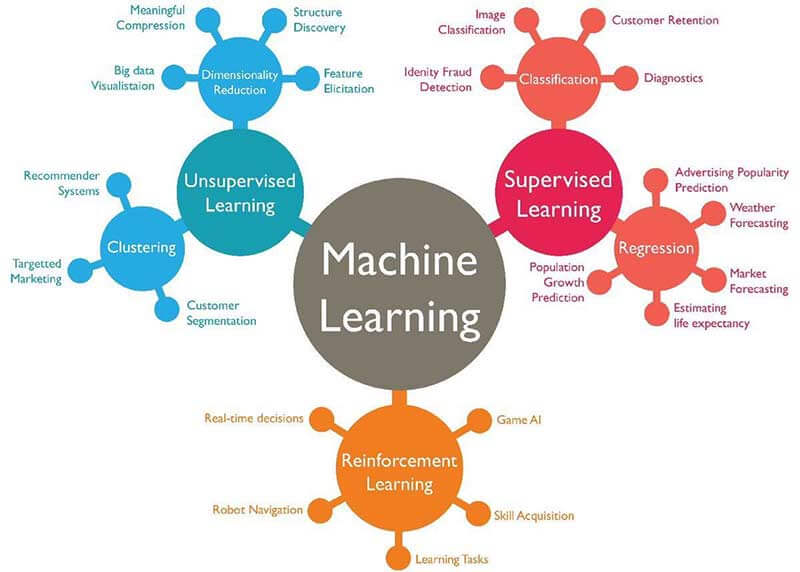
MACHINE LEARNING /AI

Machine learning (project) is an application of artificial intelligence (project) that provides systems the ability to automatically learn and improve from experience without being explicitly programmed. Machine learning (project) focuses on the development of computer programs that can access data and use it learn for themselves.
IEEE projects for CSE final year 2021-2022
Java Final year CSE projects in Bangalore
- Java Information Forensic / Block Chain B.E Projects
- Java Cloud Computing B.E Projects
- Java Big Data with Hadoop B.E Projects
- Java Networking & Network Security B.E Projects
- Java Data Mining / Web Mining / Cyber Security B.E Projects
- Java Artificaial Inteligence B.E Projects
- Java Wireless Sensor Network B.E Projects
- Java Distributed & Parallel Networking B.E Projects
- Java Mobile Computing B.E Project
MatLab Final year CSE projects in Bangalore
- Matlab Image Processing Projects for B.E Students
- MatLab Wireless Communication B.E Projects
- MatLab Communication Systems B.E Projects
- MatLab Power Electronics Projects for B.E Students
- MatLab Signal Processing Projects for B.E
- MatLab Geo Science & Remote Sensors B.E Projects
- MatLab Biomedical Projects for B.E Students
Android Final year CSE projects in Bangalore
- Android GPS, GSM, Bluetooth & GPRS B.E Projects
- Android Embedded System Application Projetcs for B.E
- Android Database Applications Projects for B.E Students
- Android Cloud Computing Projects for Final Year B.E Students
- Android Surveillance Applications B.E Projects
- Android Medical Applications Projects for B.E
- Android Embedded System Application Projetcs for B.E
- Android Database Applications Projects for B.E Students
Embedded Final year CSE projects in Bangalore
- Embedded Robotics Projects for M.tech Final Year Students
- Embedded IEEE Internet of Things Projects for B.E Students
- Embedded Raspberry PI Projects for B.E Final Year Students
- Embedded Automotive Projects for Final Year B.E Students
- Embedded Biomedical Projects for B.E Final Year Students
- Embedded Biometric Projects for B.E Final Year Students
- Embedded Security Projects for B.E Final Year